Summer is here, and so is a tasty and easy to make dish - Maharashtrian Curd Rice. I remember having this during my stay at Pune and I absolutely loved it, so I decided to make it at home, and it turned out pretty good. Here is the recipe in text and video and a link to the youtube video for those of you who want to try it too!
Enjoy!
Monday, May 07, 2012
Wednesday, February 15, 2012
Coffee (flavoured) Yogurt
It's really simple to make, delicious to eat, and a healthy food!
Procedure:
Procedure:
- Take about 1/2 tsp. instant coffee powder (Nescafe, etc...) and make a fine powder with your fingers. Put the powder in a bowl.
- Take about 21/2 tsp. sugar and add to the same bowl.
- Take about 1 cup (240 ml) of cold yogurt and mix thoroughly with the coffee powder and sugar in the bowl using a spoon.
- Once it has formed a light brown homogenous paste, eat to your heart's content!
- Enjoy!
Saturday, February 04, 2012
Broccoli Delights!!
Broccoli goes really well with Ginger, Garlic, Butter, Olive Oil, Parsley, Basil and Oregano. Any dish that includes these ingredients must necessarily be heavenly!
Here are some recipes that sound delicious!
Here are some recipes that sound delicious!
Tuesday, January 24, 2012
SQL Query Optimization - Part-9 (Covering Indexes)
To speed up query performance, use a Covering Index that covers (indexes) not just columns that will be used in the WHERE clause, but also columns that will be used in the projection list of the SELECT query.
See this video for a more detailed explanation.
See this video for a more detailed explanation.
Sunday, January 22, 2012
Converting Regular Expressions to a DFA
Instead of writing anything on this most researched topic, I'm just posting some links here.
http://www.youtube.com/watch?v=dlH2pIndNrU
http://projectsseminar.blogspot.com/2011/06/regular-expression-to-dfa.html
http://en.wikipedia.org/wiki/Regular_expression#Implementations_and_running_times
http://swtch.com/~rsc/regexp/regexp1.html
http://www.youtube.com/watch?v=dlH2pIndNrU
http://projectsseminar.blogspot.com/2011/06/regular-expression-to-dfa.html
http://en.wikipedia.org/wiki/Regular_expression#Implementations_and_running_times
http://swtch.com/~rsc/regexp/regexp1.html
Sunday, January 08, 2012
Solve this recurrence
T(n) = T(n - √n) + T(√n) + n
Post your answers/solutions in the comments. We were asked this in the final exam in CSE-548 (Analysis Of Algorithms taught by Dr. Michael Bender).
Post your answers/solutions in the comments. We were asked this in the final exam in CSE-548 (Analysis Of Algorithms taught by Dr. Michael Bender).
Ayurvedic Way of Life
Broccoli should be had fresh!!
Broccoli should be had fresh and not frozen.
- Frozen Broccoli is not as firm as Fresh Broccoli
- Frozen Broccoli doesn't taste as good as Fresh Broccoli
- Frozen Broccoli doesn't contain the broccoli stalk which is not only more nutritious, but also more fibrous than the brocolli florets
- According to this page, "frozen broccoli has twice as much sodium as fresh (up to 68 mg per 10 oz. package), about half the calcium, and smaller amounts of iron, thiamin, riboflavin, and vitamin C."
Focaccia reprise
Made Focaccia Bread again after about 2 years of absence from baking. Contains garlic, thyme, oregano, dried basil and olive oil. This is how it turned out:
 Ingredients, motivation and housing courtesy Poorvi Matani, and oven & electricity courtesy Panna Parikh. A big thanks to my teachers at IHM and my mom who encouraged my culinary streak ;)
Ingredients, motivation and housing courtesy Poorvi Matani, and oven & electricity courtesy Panna Parikh. A big thanks to my teachers at IHM and my mom who encouraged my culinary streak ;)
This version lacked rosemary since I didn't have ready access to any. Next batch should have that plus olives, sun-dried tomatoes and maybe some other veggies.
For the complete recipe:
The last post about something similar was this recipe for Garlic & Herb Chapati.

This version lacked rosemary since I didn't have ready access to any. Next batch should have that plus olives, sun-dried tomatoes and maybe some other veggies.
For the complete recipe:
- Prepare a mixture of all the herbs (seasonings, namely thyme, oregano, basil) and virgin olive oil. You can use fresh basil instead of dried basil
- Saute garlic (important step) in butter and add to the olive oil after it's somewhat cooled
- Let this sit in a closed container for anywhere between 4 hours to 1 week
- Make the bread dough as explained in this post (or any other bread dough recipe that you are comfortable with)
- After the first rise (step-7 in the post), knead in the olive oil and seasoning mixture into the dough, and let it rise a 2nd time in a flat pan (as shown in the picture above)
- After it has almost doubled in size, plonk it carefully into a pre-heated oven (410F) for ~15-20 minutes or till it's done
- Enjoy!
The last post about something similar was this recipe for Garlic & Herb Chapati.
Monday, October 24, 2011
What business do you want to be in?
Dr. Bender once mentioned in class that memories are created when one experiences joy strong emotions, and in the context of algorithms, when one discovers a solution to some problem.
About a month down, I've noticed that experiences are what I'm going to die with. I vividly remember this episode in school when we were in the middle of the gymnastics competition and were one short of someone on the roman rings. I decided to give it a shot (even though I had never tried it before) and 2 minutes later I found myself stuck "up there". I don't remember all the things that I did right or who eventually won, but I surely do remember getting stuck!
If you are from my school and remember this episode, please leave a comment. I'll be looking forward to hearing from you!
I want to be in the business of creating memories.
About a month down, I've noticed that experiences are what I'm going to die with. I vividly remember this episode in school when we were in the middle of the gymnastics competition and were one short of someone on the roman rings. I decided to give it a shot (even though I had never tried it before) and 2 minutes later I found myself stuck "up there". I don't remember all the things that I did right or who eventually won, but I surely do remember getting stuck!
If you are from my school and remember this episode, please leave a comment. I'll be looking forward to hearing from you!
I want to be in the business of creating memories.
Edit: Fixed the incorrect quote in the first line.
Tuesday, September 20, 2011
The Integer (0/1) Bounded Knapsack Problem
Quoting the problem statement from Petr's blog:
"The bounded knapsack problem is: you are given n types of items, you have ui items of ith type, and each item of ith type weighs wi and costs ci. What is the maximal cost you can get by picking some items weighing at most W in total?"
Here, we assume that the knapsack can hold a weight at most W.
We shall describe 3 solutions to this problem, each of which reduces the complexity of the solution by a certain amount.
"The bounded knapsack problem is: you are given n types of items, you have ui items of ith type, and each item of ith type weighs wi and costs ci. What is the maximal cost you can get by picking some items weighing at most W in total?"
Here, we assume that the knapsack can hold a weight at most W.
We shall describe 3 solutions to this problem, each of which reduces the complexity of the solution by a certain amount.
- O(W*n*M): The first solution is the standard knapsack solution solution, which just involves copying each item instance of every item type to get a total of ui items of the ith type, each of which represents a different item having the same wi & ci as the item of the ith type.
It is easy to see that if we have a mean of M number of items of each type, the complexity of this solution is O(W * n * M) - O(W*n*log(M)): The second solution involves rewriting items such that we have a fewer number of items of each type to work with. We shall then solve the transformed problem using the same technique as the standard knapsack problem (as in the solution above).
Suppose we have 21 instance of the ith item type, weighing wi and costing ci. We observe that 21 can be rewritten (using powers of 2) as:
21 = 1 + 2 + 4 + 8 + 6
We basically add powers of 2 till we exceed the sum we want to create (21 in this case). When we exceed the sum, we just add the difference (6 in this case) between the number (21 in this case) and the current sum we have (15 in this case = 1+2+4+8).
Now, the new items are created by combining 1, 2, 4, 8, and 6 items of the original instances. These newly created items will have the following weights and costs:
Number of items of the original type combined Weight Cost 1 1*wi 1*ci 2 2*wi 2*ci 4 4*wi 4*ci 8 8*wi 8*ci 6 6*wi 6*ci
Hence, we have effectively reduced the number of items from 21 to 5. In general, we replace the M in the solution above with log(M) to get a final complexity of O(W * n * log(M)). - O(W*n): The third and most efficient solution to this problem is the one that took me almost 3 days to figure out and understand. The short post on petr's blog actually contains all the information needed to understand it, but I'm not that comfortable reading terse explanations; especially when it's a new idea, so here is something more verbose.
There is also a paper and a section in a book dedicate to this problem, but I find them quite hard as well.
Let's assume that this row (in the DP table of Items (rows) v/s Weight (columns)) represents the best configuration (maximum cost) for the knapsack at every weight 0 .. W that includes all item types from 1 .. (k-1)
Weight 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Item (k-1) 0 5 5 7 15 15 19 20 21 23 30 33 42 42 49 51
So, the basic observation is that DP(k-1), w represents the best solution including all items from 1 .. (k-1) (both inclusive) with a knapsack of weight (w).
To compute DPk, w, we consider the possibility of including either 0, 1, 2, 3, 4, ..., ui items of the ith type to the previous best solution including all items from 1 .. (k-1). This gives us the following recurrence:
DPk, w = max (
DP(k-1), w,
DP(k-1), w-1*wk + 1*ck,
DP(k-1), w-2*wk + 2*ck,
DP(k-1), w-3*wk + 3*ck,
...,
DP(k-1), w-ui*wk + ui*ck)
An interesting observation here would be that we only deal with every wkth element from the previous array to decide on any element in the current array.
Let us for a minute ignore the fact that we have only a fixed number of items of each type and instead assume that we have an infinite number of items of each type. Let us assume that item i weighs 3 and costs 9. If we make that assumption, we see that the best solution at DPk, 12 is represented by taking the maximum of the cells colored in green below.
Weight 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Item (k-1) 0 5 5 7 15 15 19 20 21 23 30 33 42 42 49 51 36 34 37 32 42
What we have essentially done is added:
0*9 to DP(k-1), 12
1*9 to DP(k-1), 9
2*9 to DP(k-1), 6
3*9 to DP(k-1), 3 and
4*9 to DP(k-1), 0
The problem has reduced to finding the maximum value among all the values of the array that is formed by picking every wkth element from the previous best solution and adding some multiple of ck to it.
We also notice that it doesn't matter what values we add to DP(k-1), w (for the kth item) as long as they are ck apart. Hence, if the weight of the knapsack is W and the weight of the kth item is wk, we can add the following to every wkth element in the previous array.
Column to which value is added Value Added 0 (W/wk)*ck 1*wk (W/wk - 1)*ck 2*wk (W/wk - 2)*ck 3*wk (W/wk - 3)*ck
If we now reintroduce the requirement that each item type will have only a bounded or fixed number of instances (i.e. uk is bounded), then the problem reduces to finding the maximum value in every window of size uk in the array we just computed. This can easily be done by pre-processing the array to maintain the largest element in every window of size uk.
However, the actual value of the cost at any cell needs to be computed by adding back any differential that we may have subtracted to ensure that every entry is ck apart and that the first entry is the one which has the maximum multiple of ck subtracted from it. For the jth array element in the current sub-array we are processing, this value will be (W/wk - j)*ck (since we have subtracted that much extra from those elements, we must now add it back).
Hence, we can safely say that we shall have wk different sub-problems that we shall try to solve assuming that we can use a single computation for every wkth element.
This allows us to find the value at every cell of the (k x W) matrix is amortized time O(1) (we have amortized the cost of pre-computing the wk arrays across all the element accesses). This makes the total running time of this algorithm O(W * n).
Thursday, July 14, 2011
Vegetable Ratatouille
Here we go!!
So, we'll be following this recipe for the most part. There are some diversions that I shall mention here. These are the only things I changed from the recipe above.
Tomatoes: We shall make a Ratatouille that has a red (tomato) gravy and the vegetables will be added to that gravy. For this, you'll need more tomatoes (at least 4 more).
Basil: I used dry basil instead of fresh basil, since I couldn't find any where I stay. I used lesser oil at every stage (use about half the amount of oil everywhere).
Olive Oil: Do NOT use Extra-Virgin Olive Oil for cooking. Do NOT use Olive-Pomace Oil since it doesn't have a good taste. Use ONLY Pure-Olive-Oil.
Salt: ALWAYS use Salt to-taste instead of measuring it since the saltiness of salt varies from region to region.
Ginger: I also use grated ginger (or ginger paste) along with the garlic pieces.
Bay Leaf: I also used bay-leaves (3 nos.) while sautéing the onions (along with the garlic and ginger).
After the onions are half done, add pieces of (at least) 4 tomatos and cook till the tomatoes are soft. Mash them to form a paste. Follow the recipe mentioned here. Once the other vegetables are cooked, add them to this tomato gravy and cook for about 3 mins. (or till steaming). Cover and let the vegetables soak in the smell for about 15 mins. Serve with rice (you can use brown rice since it tastes really good and is a healthier option when compared with white rice).
So, we'll be following this recipe for the most part. There are some diversions that I shall mention here. These are the only things I changed from the recipe above.
Tomatoes: We shall make a Ratatouille that has a red (tomato) gravy and the vegetables will be added to that gravy. For this, you'll need more tomatoes (at least 4 more).
Basil: I used dry basil instead of fresh basil, since I couldn't find any where I stay. I used lesser oil at every stage (use about half the amount of oil everywhere).
Olive Oil: Do NOT use Extra-Virgin Olive Oil for cooking. Do NOT use Olive-Pomace Oil since it doesn't have a good taste. Use ONLY Pure-Olive-Oil.
Salt: ALWAYS use Salt to-taste instead of measuring it since the saltiness of salt varies from region to region.
Ginger: I also use grated ginger (or ginger paste) along with the garlic pieces.
Bay Leaf: I also used bay-leaves (3 nos.) while sautéing the onions (along with the garlic and ginger).
After the onions are half done, add pieces of (at least) 4 tomatos and cook till the tomatoes are soft. Mash them to form a paste. Follow the recipe mentioned here. Once the other vegetables are cooked, add them to this tomato gravy and cook for about 3 mins. (or till steaming). Cover and let the vegetables soak in the smell for about 15 mins. Serve with rice (you can use brown rice since it tastes really good and is a healthier option when compared with white rice).
Wednesday, July 06, 2011

Friday, June 10, 2011
A plea to all software developers: Use Units
Have you ever come across configuration files that read:
WTF!!
4096 what?? bits, bytes, kilobytes, megabytes?
20 what?? mill-second, second?
Please, please make units part of the config. option and say:
MAX_BUFFER_SIZE = 4096 MAX_TIMEOUT = 20
WTF!!
4096 what?? bits, bytes, kilobytes, megabytes?
20 what?? mill-second, second?
Please, please make units part of the config. option and say:
MAX_BUFFER_SIZE_BYTES = 4096 MAX_TIMEOUT_MILLISEC = 20
Sunday, May 15, 2011
Why DuckDuckGo is good for mother
My mother wastes a lot of time online visiting MFA sites because she can't differentiate between the legitimate ones and the scammy ones. I've set up DuckDuckGo for her as her default search engine and she's been complaining lesser about "Why does this site not have what I want?".
I also feel that DDG can have a bang page organized by target audience (such as Mother/Father/Student, etc...). For Mother, these would need to go in:
It would surely make it easier for mother to navigate the shortcuts!!
I also feel that DDG can have a bang page organized by target audience (such as Mother/Father/Student, etc...). For Mother, these would need to go in:
- !allrecipes
- !epicurious
- !w
- !yt
- !lyrics
- !gimages
- !gmaps
- !bloomberg
- !reuters
- !songmeanings
- !news
It would surely make it easier for mother to navigate the shortcuts!!
Sunday, May 08, 2011
Faster Javascript String matching
Ever had to match a lot of strings (say article titles or names of people) to a user entered query? I'm sure you always:
Well, it turns out that both are suboptimal. Let us for a minute assume that the data you have is relatively static (doesn't change too much over time) and that queries really should be satisfied quickly. If that is the case, then you would be better off:
Assuming that the regular expression engine is optimized (and mostly they are), a regexp match would be much faster than a naive O(n2) search.
Let's look at some code and the resulting running time for either approach.
This is the output that running this code produces:
Which means that the longer code is actually 2.63 times faster than the more beautiful looking code.
When the difference between 200ms and 300ms is felt by the user (for UI centric applications), this can be a huge improvement to the perceived responsiveness of the application.
- Looped around the values and
- Performed a substring search on these strings
Well, it turns out that both are suboptimal. Let us for a minute assume that the data you have is relatively static (doesn't change too much over time) and that queries really should be satisfied quickly. If that is the case, then you would be better off:
- Maintaining all the data to be queried in a single string (delimited by a $ or # sign - something that is not expected to be present in the data itself)
- Performing a regular-expression match on the aforementioned string
Assuming that the regular expression engine is optimized (and mostly they are), a regexp match would be much faster than a naive O(n2) search.
Let's look at some code and the resulting running time for either approach.
function random_string(len) {
var s = '';
for (var i = 0; i < len; ++i) {
s += String.fromCharCode(Math.round(97 + Math.random()*26));
}
return s;
}
var rs = [ ];
var total_length = 0;
// Stores the start index of each string in rs.join('$');
var indexes = [ ];
for (var i = 0; i < 300000; ++i) {
var s = random_string(40);
rs.push(s);
indexes.push(total_length);
total_length += (s.length + 1);
}
function test_01(rs) {
// Returns the number of elements in 'rs' that match the regexp /ret/
var re = /ret/g;
var cnt = 0;
for (var i = 0; i < rs.length; ++i) {
var m = rs[i].match(re);
if (m) {
cnt += 1;
}
}
return cnt;
}
function test_02(rs) {
// Returns the number of elements in 'rs' that match the regexp /ret/
var re = /ret/g;
var s = rs.join('$');
// Indexes of strings in 'rs' that matched
var idx = [ -1 ];
var ii = 0;
var m = re.exec(s);
while (m) {
while (ii < indexes.length && indexes[ii] <= m.index) {
++ii;
}
if (idx[idx.length-1] != ii) {
idx.push(ii);
}
m = re.exec(s);
}
return idx.length - 1;
}
d1 = new Date();
console.log("test_01:", test_01(rs));
d2 = new Date()
console.log("test_01 time:", d2-d1);
d1 = new Date();
console.log("test_02:", test_02(rs));
d2 = new Date()
console.log("test_02 time:", d2-d1);
This is the output that running this code produces:
test_01: 665 test_01 time: 935 test_02: 665 test_02 time: 257
Which means that the longer code is actually 2.63 times faster than the more beautiful looking code.
When the difference between 200ms and 300ms is felt by the user (for UI centric applications), this can be a huge improvement to the perceived responsiveness of the application.
Computing the Cumulative sum of a range of elements in a binary tree
Let us assume the alternative definition of a BST (Binary Search Tree), namely: "The left subtree shall contain elements less than or equal to the element at the root and the right subtree shall contain elements greater than or equal to the element at the root".
This means that if we want to compute the cumulative sum of all numbers ≤ to a given number, we need to update some metadata every time a node is added to the tree or removed from the tree (and for a balanced BST also when rebalancing occurs). Fortunately, this implementation of the AVL Tree allows us to do just this by way of hook functions that you can pass to it via the constructor.
We define a function binary_tree_summer that computes the cumulative sum of a node and its child nodes and stores in the sum attribute of the node.
To query the cumulative sum, we define a function query_sum that basically employs the following strategy (given our definition of the BST above):
You can see that at every stage, we decide to go either left or right, which means that our runtime is bounded by the height of the tree, which fortunately in case of an AVL Tree is at most O(log n).
The code for such a use-case is shown below:
Let's look at summing all numbers ≤ 2. The diagram below shows us how the call flow looks like. Note:

The sum is obtained in the following manner for values ≤ 2: 47-39+4
The diagram below shows us the call flow for summing all numbers ≤ 5.

The sum is obtained in the following manner for values ≤ 5: 47-39+39-25+25-16
This means that if we want to compute the cumulative sum of all numbers ≤ to a given number, we need to update some metadata every time a node is added to the tree or removed from the tree (and for a balanced BST also when rebalancing occurs). Fortunately, this implementation of the AVL Tree allows us to do just this by way of hook functions that you can pass to it via the constructor.
We define a function binary_tree_summer that computes the cumulative sum of a node and its child nodes and stores in the sum attribute of the node.
To query the cumulative sum, we define a function query_sum that basically employs the following strategy (given our definition of the BST above):
- If the value at the node is ≤ than the value we are looking for, we take the cumulative sum at the node, subtract from it the sum in it's right subtree (since we don't know how many elements in the right subtree will match our query) and then add the result of querying the right subtree
- If the value at the node is > the value we are looking for, we are assured that the complete range lies in the node's left subtree, so we query the left subtree
You can see that at every stage, we decide to go either left or right, which means that our runtime is bounded by the height of the tree, which fortunately in case of an AVL Tree is at most O(log n).
The code for such a use-case is shown below:
function cumulative_sum() {
var items = [ 4, 9, 2, 5, 4, 2, 1, 2, 3, 2, 1, 7, 3, 2 ];
function binary_tree_summer(node) {
var _s = (node.left ? node.left.sum : 0) +
(node.right ? node.right.sum : 0) + node.value;
node.sum = _s;
}
var tree = new algo.AVLTree(algo.cmp_lt, binary_tree_summer);
for (var i = 0; i < items.length; ++i) {
tree.insert(items[i]);
}
function query_sum(node, value) {
// We do the query like we do for a Segment Tree
if (!node) {
return 0;
}
if (node.value <= value) {
var sub = node.right ? node.right.sum : 0;
return node.sum - sub + query_sum(node.right, value);
}
else {
// node.value > value
return query_sum(node.left, value);
}
}
console.log("<= 2:", query_sum(tree.root, 2));
console.log("<= 5:", query_sum(tree.root, 5));
Let's look at summing all numbers ≤ 2. The diagram below shows us how the call flow looks like. Note:
- The green lines are the paths followed down the root
- The red lines are the paths that are rejected (not followed)
- The numbers in blue above each node denote the value of the sum attribute for that node
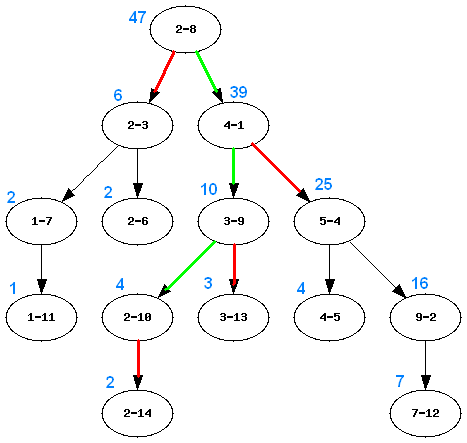
The sum is obtained in the following manner for values ≤ 2: 47-39+4
The diagram below shows us the call flow for summing all numbers ≤ 5.

The sum is obtained in the following manner for values ≤ 5: 47-39+39-25+25-16
Binary Trees with Repeated elements
In school/college, we all learnt about Binary Trees and while we were taught how to implement them, the implicit assumption was that elements would not be repeated. However, in the real-world, we need to deal with repeated elements all the time. Most standard library implementations of popular languages (read Java) provide a TreeMap that is reduced to something very powerless because it doesn't support repeated elements!! The C++ std::multimap class however supports repetitions and is IMHO much more powerful than any other Balanced Binary Tree implementation that I have come across.
Today, I shall make an attempt to de-mistify the process of creating a Binary Tree with repeated elements. It's really simple and I think that the process can be summarized in one sentence: "Instead of the left subtree containing elements strictly less than the element at the root and the right subtree containing elements strictly greater than the element at the root, the left subtree shall contain elements less than or equal to the element at the root and the right subtree shall contain elements greater than or equal to the element at the root". Simple, isn't it!!
Now, let's see why it works.
The simple case of asking whether an element exists or not can be easily implemented the same way as before. If the element is present, we shall hit it while traversing down the tree.
Finding the first instance of an element (if it exists) is called locating the lower_bound of that element. This can be accomplished by running down the left of the node till you have an element at the node that is greater than or equal to the element to be found. We keep a track of the node every time we take a left turn. Othwerise (the element at the node is less than the element we are interested in), we go down the right. Since the lower_bound of an element is never less than the element itself, we don't keep track of nodes when we take a right turn.
Finding one-past the last instance of an elemnt (if it exists) is called locating the upper_bound of that element. This can be accomplished by running down the left of the node till you have an element at the node that is greater than the element to be found. We keep a track of the node every time we take a left turn. Othwerise (the element at the node is less than or equal to the element we are interested in), we go down the right. Since the upper_bound of an element is never less than or equal to the element itself, we don't keep track of nodes when we take a right turn.
On the following pages, can find very high quality implementations of a Red-Black Tree and an AVL Tree respectively that both support repeated elements as well as the lower_bound and upper_bound functions.
No special handling is required during re-balancing the tree during an insertion or a deletion.
Here is a sample instance of the AVL Tree after the following elements have been inserted into it in this same order (the numbers after the - sign are just to disambiguate nodes with the same key while plotting the tree):

Today, I shall make an attempt to de-mistify the process of creating a Binary Tree with repeated elements. It's really simple and I think that the process can be summarized in one sentence: "Instead of the left subtree containing elements strictly less than the element at the root and the right subtree containing elements strictly greater than the element at the root, the left subtree shall contain elements less than or equal to the element at the root and the right subtree shall contain elements greater than or equal to the element at the root". Simple, isn't it!!
Now, let's see why it works.
The simple case of asking whether an element exists or not can be easily implemented the same way as before. If the element is present, we shall hit it while traversing down the tree.
Finding the first instance of an element (if it exists) is called locating the lower_bound of that element. This can be accomplished by running down the left of the node till you have an element at the node that is greater than or equal to the element to be found. We keep a track of the node every time we take a left turn. Othwerise (the element at the node is less than the element we are interested in), we go down the right. Since the lower_bound of an element is never less than the element itself, we don't keep track of nodes when we take a right turn.
Finding one-past the last instance of an elemnt (if it exists) is called locating the upper_bound of that element. This can be accomplished by running down the left of the node till you have an element at the node that is greater than the element to be found. We keep a track of the node every time we take a left turn. Othwerise (the element at the node is less than or equal to the element we are interested in), we go down the right. Since the upper_bound of an element is never less than or equal to the element itself, we don't keep track of nodes when we take a right turn.
On the following pages, can find very high quality implementations of a Red-Black Tree and an AVL Tree respectively that both support repeated elements as well as the lower_bound and upper_bound functions.
No special handling is required during re-balancing the tree during an insertion or a deletion.
Here is a sample instance of the AVL Tree after the following elements have been inserted into it in this same order (the numbers after the - sign are just to disambiguate nodes with the same key while plotting the tree):
4, 9, 2, 5, 4, 2, 1, 2, 3, 2, 1, 7, 3, 2

Saturday, May 07, 2011
Computing the Running Median of an Array of numbers
The problem of computing the running median of an array of numbers involves choosing a window size for which you want to compute the median for. For example, suppose you have the following list of 10 integers:
and you want to compute the running median for a window of size 7, you will get the following list of 4 medians:
The naive way would be to always sort the array and pick the middle element. This costs O(n.log n) per operation (when an integer leaves and enters the window). A slightly smarter solution will try to keep the array sorted and remove and insert the integers in O(n) time. Even though this is better, we hope to do better.
You can find many resources online that try to solve the problem, but surprisingly, very few mention an O(log n) solution (per insertion and removal of an integer), which I believe is quite easy to implement.
I shall first describe a general (data structure independent) procedure for computing the running median of a set of integers and provide other specific tricks that use a balanced binary tree to achieve the same.
General Technique:
The general technique involves keeping the data (we assume that all integers are distinct for the sake of simplicity) partitioned into 3 sets, namely:
Set-1 should support the following operations with the below mentioned runtime complexity:
Any operation on Set-2 is pretty trivial to implement, so I'll skip to the next set.
Set-3 should support the following operations with the below mentioned runtime complexity:
What we shall do is initially sort the first 'k' (window size) elements in the stream and create the 3 sets as described above. We also maintain a queue of handles as returned by each of the data structures managing Sets 1 & 3. This will help us remove the oldest element from these sets.
When a new integer is to be inserted, we follow these steps:
If we follow the steps mentioned above, we are ensured that the median is always present in Set-2 (Set-2 always has just 1 element).
A Max-Heap can be used to implement Set-1 and a Min-Heap can be used to implement Set-3. Alternatively, a Min-Max-Heap can be used to implement both. We can also use a balanced binary tree (such as an AVL Tree, Red-Black Tree, AA Tree) to implement Sets 1 & 3.
Balanced Binary Tree Technique:
We can use a Balanced Binary Tree such as an AVL Tree or a Red-Black Tree with order-statistic querying to implement the running median algorithm. Insertions and deletions can be performed in O(log n) time (as before, we maintain a queue of the elements - we do not need handles in this case since a balanced binary tree can delete an element in O(log n) given the element's value). Furthermore, we can query the tree for the WINDOW_SIZE/2 ranked element (which is the median) at every stage. This is by far the simplest and cleanest technique. You can find an implementation of an AVL Tree that supports querying the k-th smallest element (for any k) here.
Example code to use the AVLTree linked above:
4, 6, 99, 10, 90, 12, 17, 1, 21, 32
and you want to compute the running median for a window of size 7, you will get the following list of 4 medians:
Median for 4, 6, 99, 10, 90, 12, 17 : 12 Median for 6, 99, 10, 90, 12, 17, 1 : 12 Median for 99, 10, 90, 12, 17, 1, 21 : 17 Median for 10, 90, 12, 17, 1, 21, 32 : 17
The naive way would be to always sort the array and pick the middle element. This costs O(n.log n) per operation (when an integer leaves and enters the window). A slightly smarter solution will try to keep the array sorted and remove and insert the integers in O(n) time. Even though this is better, we hope to do better.
You can find many resources online that try to solve the problem, but surprisingly, very few mention an O(log n) solution (per insertion and removal of an integer), which I believe is quite easy to implement.
- http://mail.python.org/pipermail/python-list/2009-October/1222595.html
- http://stats.stackexchange.com/questions/134/algorithms-to-compute-the-running-median
- http://stats.stackexchange.com/questions/3372/is-it-possible-to-accumulate-a-set-of-statistics-that-describes-a-large-number-of/3376
- http://code.activestate.com/recipes/577059-running-median/
I shall first describe a general (data structure independent) procedure for computing the running median of a set of integers and provide other specific tricks that use a balanced binary tree to achieve the same.
General Technique:
The general technique involves keeping the data (we assume that all integers are distinct for the sake of simplicity) partitioned into 3 sets, namely:
- All elements less than the median
- The median
- All elements greater than the median
Set-1 should support the following operations with the below mentioned runtime complexity:
- Insertion of an element: O(log n)
- Removal of an arbitrary element (given its handle - the handle is returned by the data structure when the element is inserted): O(log n)
- Query the maximum valued element: O(log n)
Any operation on Set-2 is pretty trivial to implement, so I'll skip to the next set.
Set-3 should support the following operations with the below mentioned runtime complexity:
- Insertion of an element: O(log n)
- Removal of an arbitrary element (given its handle - the handle is returned by the data structure when the element is inserted): O(log n)
- Query the minimum valued element: O(log n)
What we shall do is initially sort the first 'k' (window size) elements in the stream and create the 3 sets as described above. We also maintain a queue of handles as returned by each of the data structures managing Sets 1 & 3. This will help us remove the oldest element from these sets.
When a new integer is to be inserted, we follow these steps:
- Get the handle to the oldest element and remove it from the set in which it currently is
- Insert the new element in Set-1 (or Set-3) and push the returned handle into the queue
- If the median element goes missing, we pick up the largest element from Set-1 (or the smallest element from Set-3), remove that from the set and set that as the median element
- If we notice that the sizes of Sets 1 & 3 are not within 1 of each other, we shift the elements via the median from one set to the other
- We always shift the largest element from Set-1 or the smallest element from Set-3
- We ensure that the handles get updated whenever the elements move from one set to the other. This requires the handle to be smart and contain a reference to its parent set
If we follow the steps mentioned above, we are ensured that the median is always present in Set-2 (Set-2 always has just 1 element).
A Max-Heap can be used to implement Set-1 and a Min-Heap can be used to implement Set-3. Alternatively, a Min-Max-Heap can be used to implement both. We can also use a balanced binary tree (such as an AVL Tree, Red-Black Tree, AA Tree) to implement Sets 1 & 3.
Balanced Binary Tree Technique:
We can use a Balanced Binary Tree such as an AVL Tree or a Red-Black Tree with order-statistic querying to implement the running median algorithm. Insertions and deletions can be performed in O(log n) time (as before, we maintain a queue of the elements - we do not need handles in this case since a balanced binary tree can delete an element in O(log n) given the element's value). Furthermore, we can query the tree for the WINDOW_SIZE/2 ranked element (which is the median) at every stage. This is by far the simplest and cleanest technique. You can find an implementation of an AVL Tree that supports querying the k-th smallest element (for any k) here.
Example code to use the AVLTree linked above:
var algo = require('algorithm');
var items = [4, 6, 99, 10, 90, 12, 17, 1, 21, 32];
function print_median(tree) {
console.log("Median:", tree.find_by_rank(Math.ceil(tree.length / 2)));
}
function running_median(items, window_size) {
var tree = new algo.AVLTree();
for (var i = 0; i < items.length; ++i) {
tree.insert(items[i]);
if (tree.length == window_size) {
print_median(tree);
tree.remove(items[i - window_size + 1]);
}
}
}
running_median(items, 7);
Monday, April 18, 2011
Bajra Roti/Parantha
Ingredients:
Procedure:
| Bajra atta (Pearl millet flour): | 2 cups |
| Water: | Enough to bind the flour (keep 2 cups handy) |
Procedure:
- Add little water and try to bind the flour. Keep adding a water as and when required
- Once the flour is hydrated, add a little more water to make it smooth
- Take a plastic sheet and place it on the chakla (flat circular rolling board)
- Ensure that you heat the tava (flat skillet) before you begin. Turn the flame to low when it is heated up
- Take about 100-150g of dough and place it on the plastic sheet
- Sprinkle some millet flour on top of it so that it doesn't stick to your hand
- Using your hand, gently press down the dough ball into a flat circular disc - rotating the dough all the time. It should be easy to rotate the dough since the plastic sheet will slide very easily on the rolling board
- Keeping the flame on low, place the flattened dough (top side down) on the tava
- Once you see small bubbles popping up on the surface, turn the roti over
- Heat till you see brown spots on the under-surface
- Turn the flame to high and momentary place the roti (turned over again) on the flame directly. This should make the roti balloon. The ballooning of the roti means that it has been cooked properly
- Turn over to other side to cook consistently (as desired - but don't burn it please!!)
- Serve with dahi (curd), butter, jaggery and vegetables. Enjoy!!
Subscribe to:
Posts (Atom)